What is data automation?
Data automation is the process of updating data on your open data portal programmatically, rather than manually. Automating the process of data uploading is important for the long-term sustainability of your open data program. Any data that is updated manually risks being delayed because it is one more task an individual has to do as part of the rest of their workload.
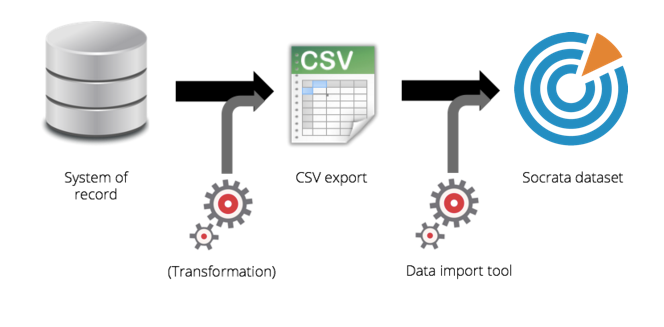
There are three common elements to data automation: Extract, Transform, and Load, or ETL.
- Extract: the process of extracting your data from one or many sources systems
- Transform: the process of transforming your data into the necessary structure, such as a flat file format like a CSV. This could also include things like changing all state abbreviations to the full state name.
- Load: the process of loading the data into the final system, in this case the open data portal.
Each one of these processes is critical to fully automating your data uploads, and doing it successfully. Below is a diagram of a standard ETL process:
What is your data automation strategy?
Before diving into the technical nitty-gritty of data automation, it is important to determine a general data automation strategy for your organization. Having a strategy beforehand will help you engage the right people at the right time within your organization.
Who owns data automation in your organization?
Depending on your team model, different groups will own different parts of the ETL process:
Centralized: Central IT organization owns the full ETL process and all data automation.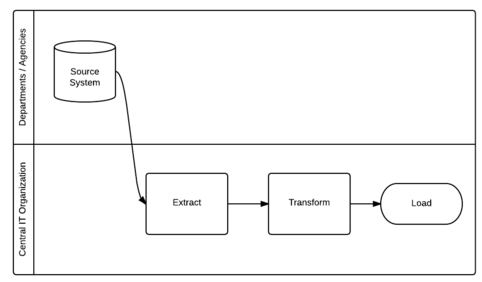
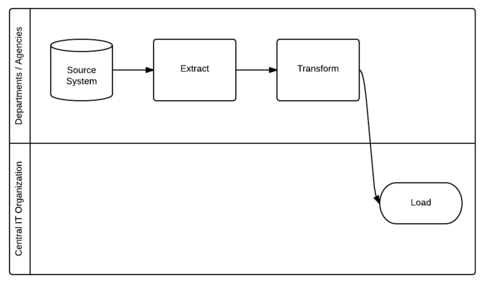
Hybrid: This model may vary, but often the individual agencies/departments will own the extract and transform processes, and the central IT organization will own the loading process.
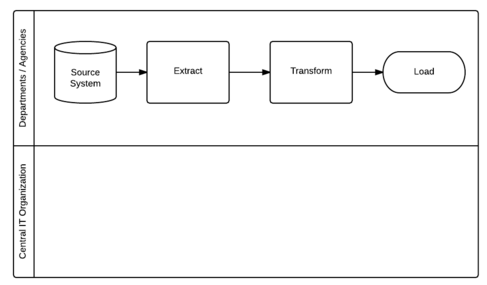
Decentralized: The individual agencies/departments will each own their own ETL process.
What tools are available for data automation?
Data automation tools vary in which process they are best suited, the technical knowledge needed to use them, and the cost. Below is a table outlining the most common tools used in automation:
|
E, T, or L? |
Technical Knowledge |
Cost |
|
|
DataSync |
L |
Medium |
Free |
|
FME |
E, T, and L |
Medium |
Yes |
|
Pentaho Kettle |
E and T |
High |
Discontinued |
|
Soda API |
L |
High |
Free - but will require developer time for custom scripts |
Beyond these tools, you can also employ a developer to create custom scripts for any of the E, T, or L processes. While this method provides more flexibility, it is more time and resource intensive.
How does automation fit into your publishing workflow?
After you have defined where the ETL stages will live within your organization, the next step is determining where your automation steps will fit into your publishing workflow. As you create your publishing flowchart, make sure to clarify the steps for Extract, Transform, and Load, as well as the individuals who will own those steps. Two of the key individuals who are likely to be involved with automation are the Data Custodian and the Data Steward.
What data should be automated?
As much data as possible! The more that you adopt an “automate by default” approach to uploading data, the less resources you will need long term for maintaining high data quality. Here are some tips for finding candidate datasets for automatic uploads:
- Is the dataset updated quarterly or more frequently?
- Are there transformations or any form of manipulation that needs to be done to the dataset prior to uploading?
- Is the dataset large (greater than 250MB)?
- Can you only get the changed rows for each subsequent update (rather than the full file)?
- Is it possible to get data from the source system, rather than from an individual?
Datasets that prompt a “yes” to any of the questions above are great candidates for automating updates, because automation can remove the risk of a lack of time and resources later on.
Quick-start steps for automation
Once you understand the landscape of data automation within your organization, you can start putting your automation strategy to use. Here are some steps to get started:
- Identify data: Select 1-2 high-value datasets where getting access to the source systems will be easy. (i.e. start with the low-hanging fruit)
- Refer to your source system inventory to determine which source systems you already have access to.
- Determine access: Determine how either the central IT organization or the department/agency will obtain the data. Will it be through a SQL query, download of a CSV, etc?
- The Data Custodian will need to be involved in this step, as they are the best resource for accessing a dataset’s source system.
- Define transformations: Outline any transformations required for that dataset. This might be as simple as changing complex acronyms to full-text names, or as complicated as transforming a relational database into a flat-CSV file.
- Work with both the Data Steward and the Data Custodian to understand which fields need to be pulled and how they should be formatted for publication.
- Develop and test ETL process: Based on the requirements defined in steps 2 and 3, select an ETL publishing tool, and publish the dataset to the Open Data Portal. Confirm that the dataset has been successfully loaded or updated through your process without errors.
- Schedule: Schedule your dataset for timely updates.
- Refer to metadata fields about data collection, refresh frequency, and update frequency you collected as part of your data inventory or dataset submission packet.
Technical resources for getting started
As you define your automation strategy and start working on automating those first few datasets, you’ll inevitably start getting into some of the technical details. Take a look at these guides to learn more about the different automation tools, and then speak with your Project Manager or Customer Success Manager to talk through next steps for getting your process implemented.
Comments
Article is closed for comments.