Before beginning the process of creating a new dataset, log in to your Data & Insights domain. Once logged in, there will be a blue navigation bar at the top of the page. From there, you can select the plus icon and click on the Select button in the Dataset tile to start making your new dataset.
Note: Don't see the “Create” button? Please check that you have the appropriate user role to upload a dataset, here.
Upon creating a new dataset you will be prompted for a dataset name and then brought to the draft page for the dataset. The top of the page will provide four data actions: Add Data, Review & Configure Data, Edit Dataset Metadata, and Edit Column Metadata. Both Review & Configure Data and Edit Column Metadata will be available after the first data is initially uploaded.
**The dataset title can be edited later on before publishing, so feel free to put in placeholder text if you need more time.**
Choosing a data source
There are a number of options for populating this dataset. Click on the Add Data button to get started with selecting a data source.
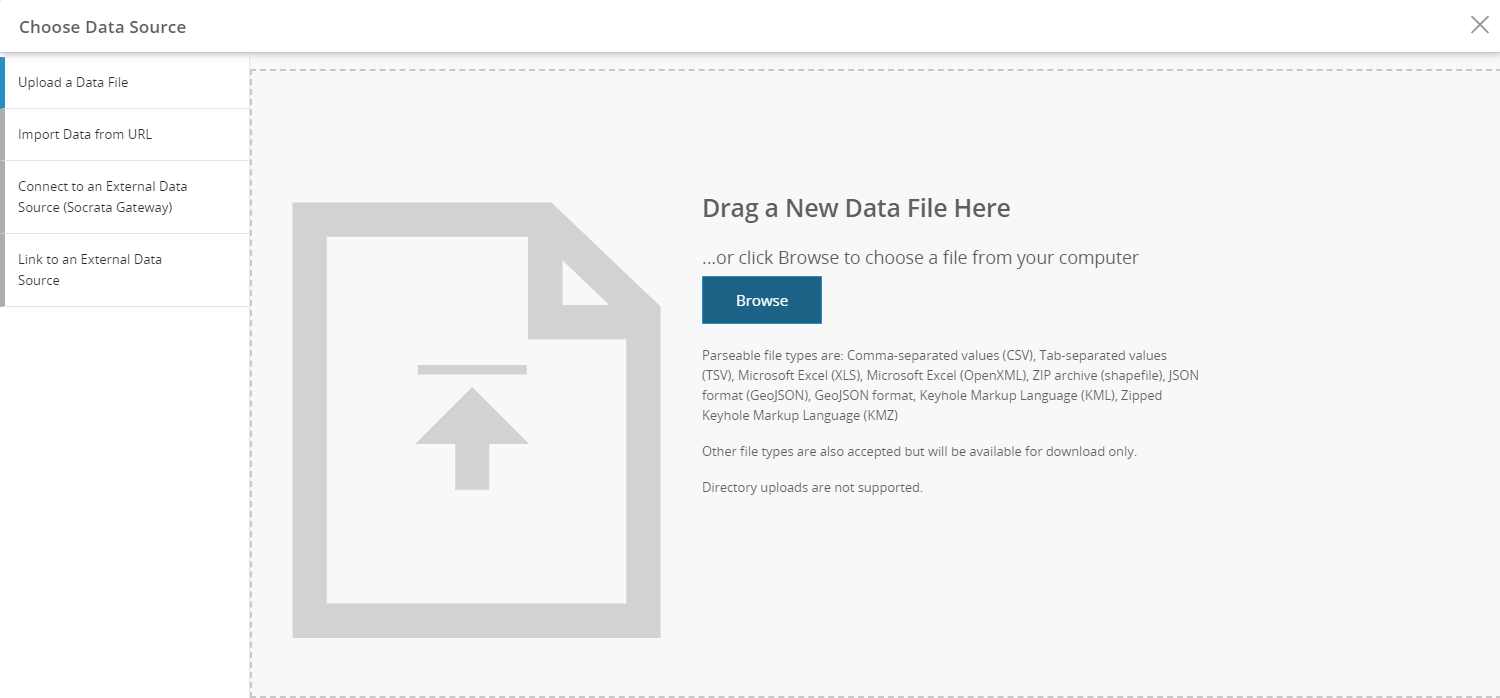
Uploading a data file
From this tab, you can upload tabular & geospatial data, in the formats of .csv, .tsv, .xls, .xlsx, .zip (shapefile), .json (GeoJSON), .geojson, .kml, .kmz, by dragging the file into the right-hand box or by browsing for the source file on your computer. You can also upload unstructured data files. For a full list, see our article on accepted source files.
Uploading a file without parsing
Clicking the link in the of the Upload A Data File tab will allow you to upload a file without parsing it. This link allows you to add large files to the data catalog without turning it into a dataset on the platform.
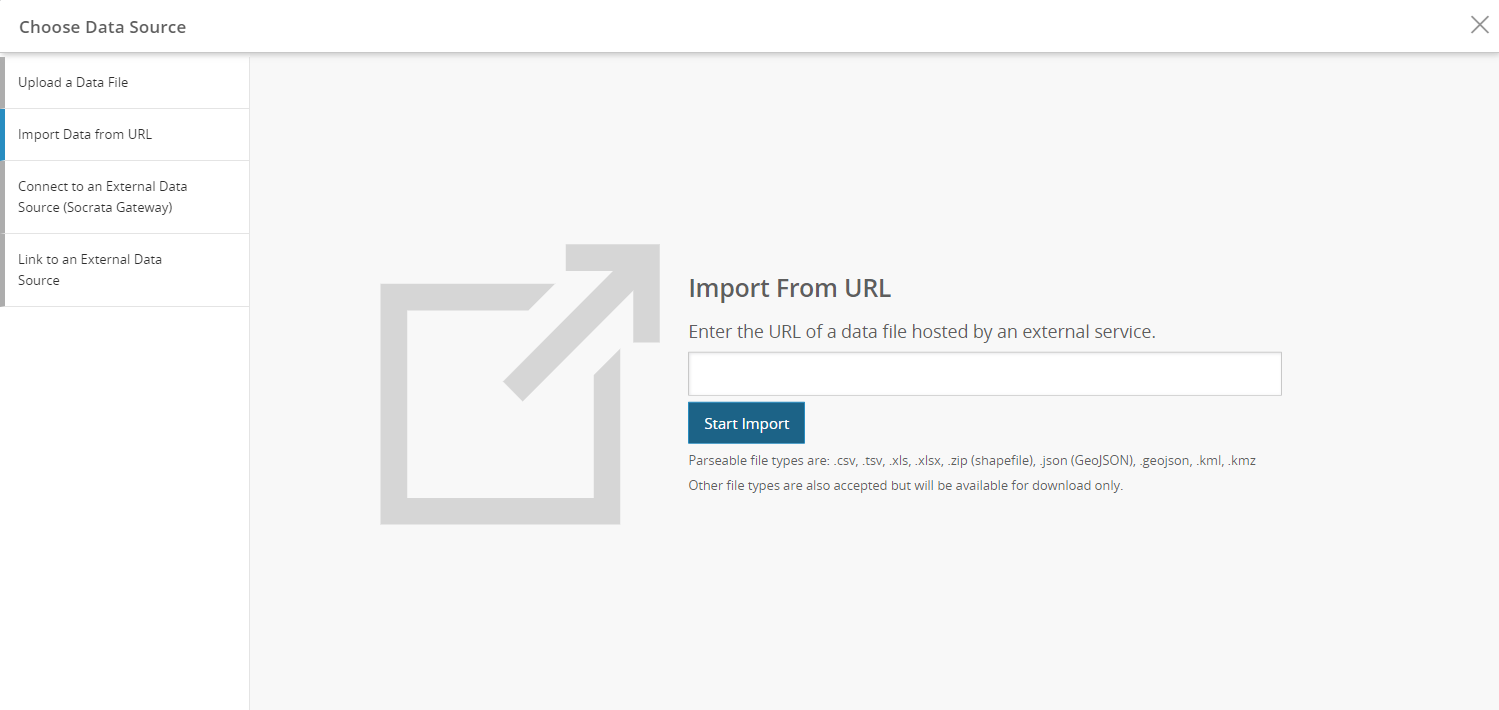
Importing data from a URL
From this tab, you can import a tabular or geospatial dataset (.csv, .tsv, .xls, .xlsx, .zip (shapefile), .json (GeoJSON), .geojson, .kml, .kmz file types) that is hosted externally.
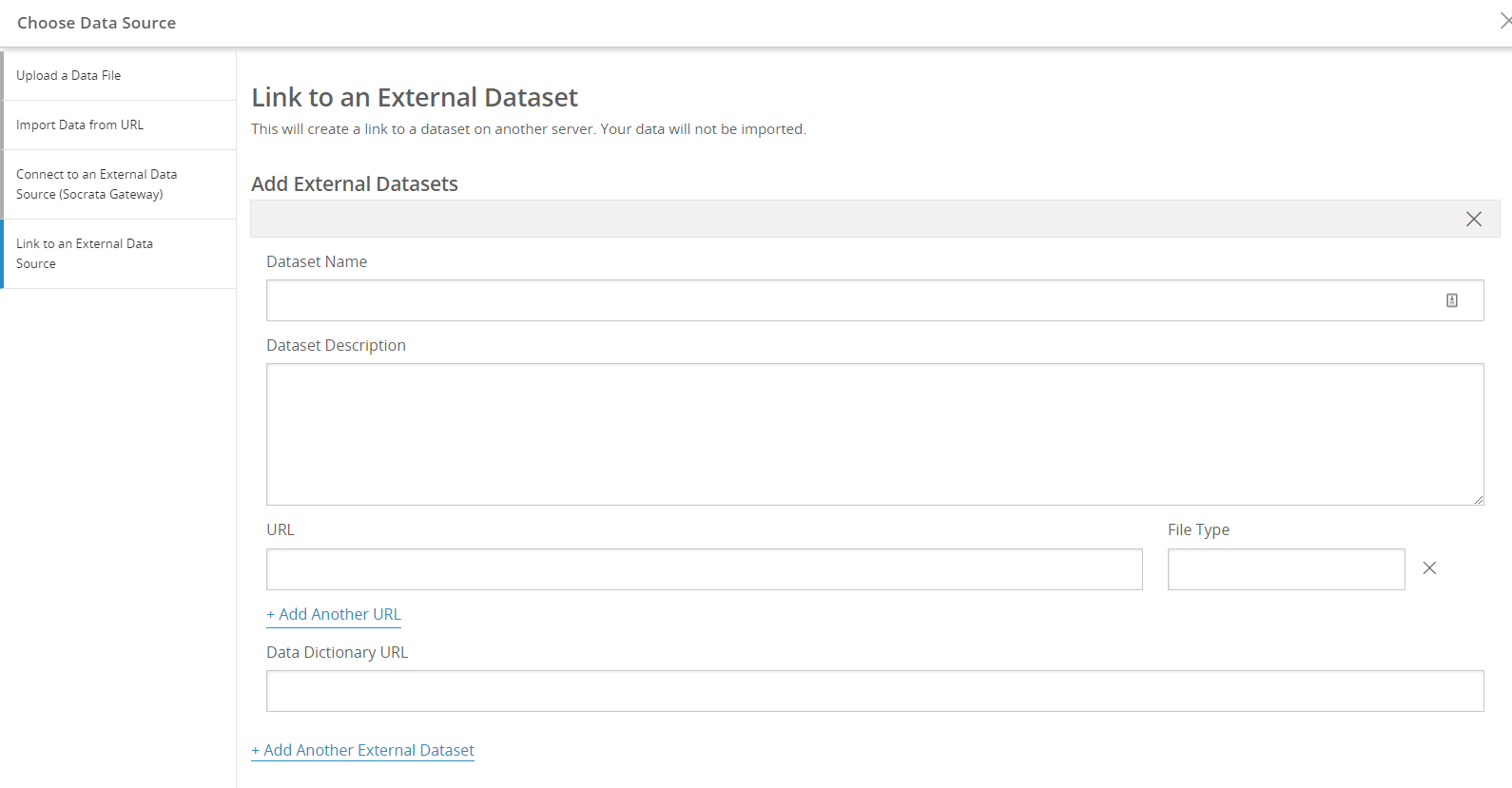
Linking to an external data source
Alternatively, you can link to an external data source. You will be able to link multiple files to one dataset and link multiple datasets to the overall external data source.
Reviewing data
After importing tabular data, a data table preview will be available for you to review and modify.
Editing data inline
You can now edit individual cells directly in the dataset, more information on this can be found here.
Guessing column data types
The import process does its best to guess what each column represents - numbers, text, dates and times or true/false values. It does this by taking a sample from the beginning of a file and trying out every possible type for every column. The data type with the fewest errors is selected.
We recommend that you review the data types we automatically guess for you, and you can override any guess by making a different selection in the data type dropdown, under the column name.
This is particularly important when importing a file with a large number of columns. As mentioned above, during the import process, a sample is taken from the beginning of the file. If the number of columns is quite large, the number of rows sampled may decrease, and the system will be less certain of the correct data type.
Importing errors
Any records with errors recognized by the tool will not be imported at all. Note that this is a departure from our previous upload tool’s handling of errors. More details of the errors can be accessed underneath the column data type:

Or by using the Export Errors button:

This will only export records that could not be uploaded. The file will also contain more detail on why a row will not be imported.
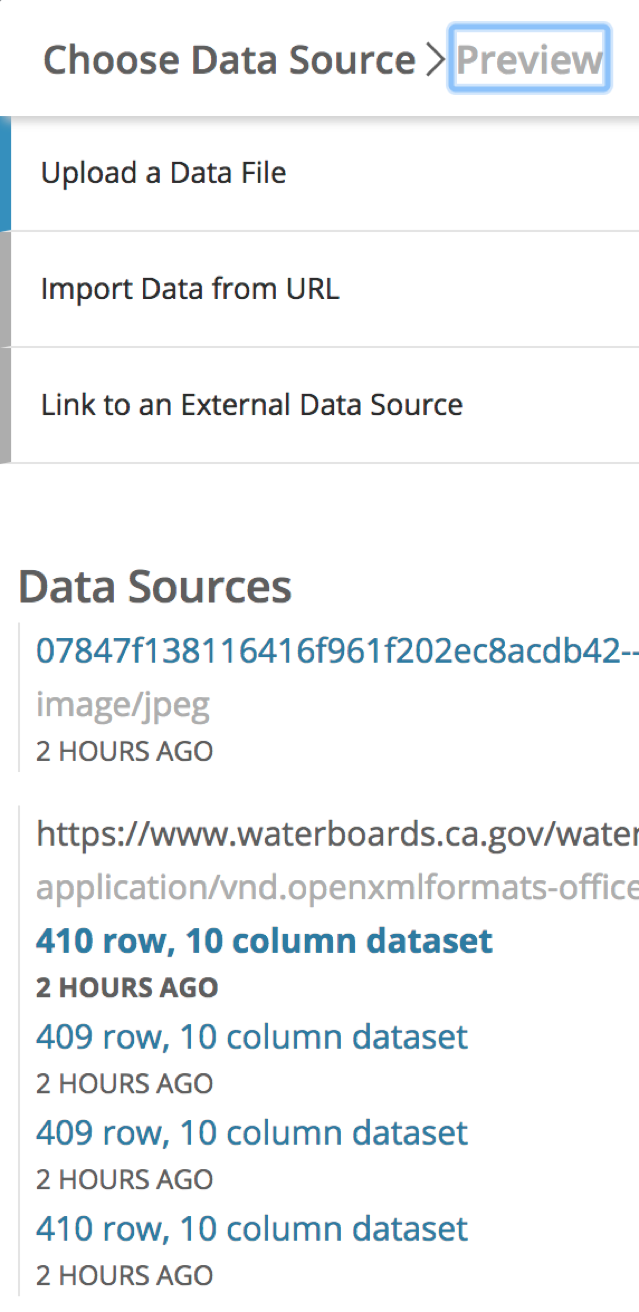
If the errors cannot be resolved by selecting a different data type, you can update your dataset in an external tool, then select the new data source to import with by going back to the ‘Choose Data Source’ tab from the ‘Preview’ screen.
Note: After a data source has been imported, changing the data source to link to an external source will no longer be possible. The restriction also exists if you start with linking to an external data source, you will not be able to change to importing a data source.
If you need to change or import a new version of the source file to this dataset, you can do so from this page. Additionally, from the Data Sources list, you can revert to a previously imported dataset.
Dataset-level formatting
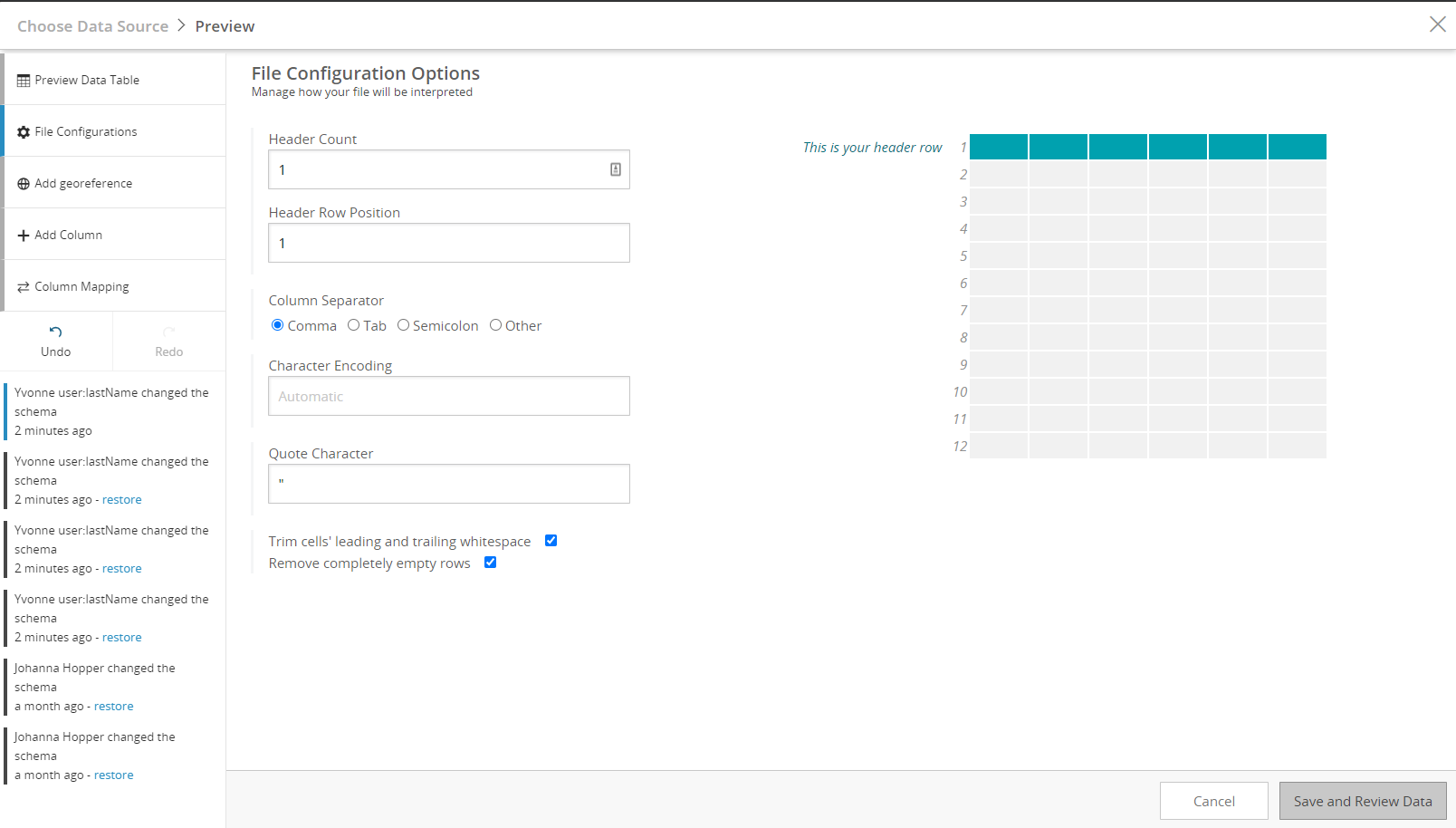
From the Preview window, you will be able to configure the dataset by designating the header row, column separator, character encoding of the source file, and quote character. From the sidebar, you can add a new column or a georeferenced location column using location data from the dataset.
Column-level formatting and transformations
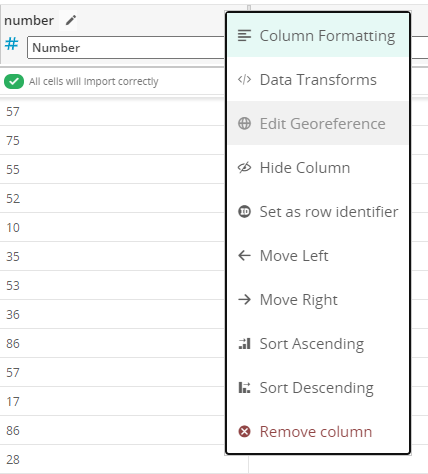
From the data table preview, you can perform the column level actions: select a data type, adjust column formatting, perform data transforms, remove columns from the dataset, and reorder the columns.
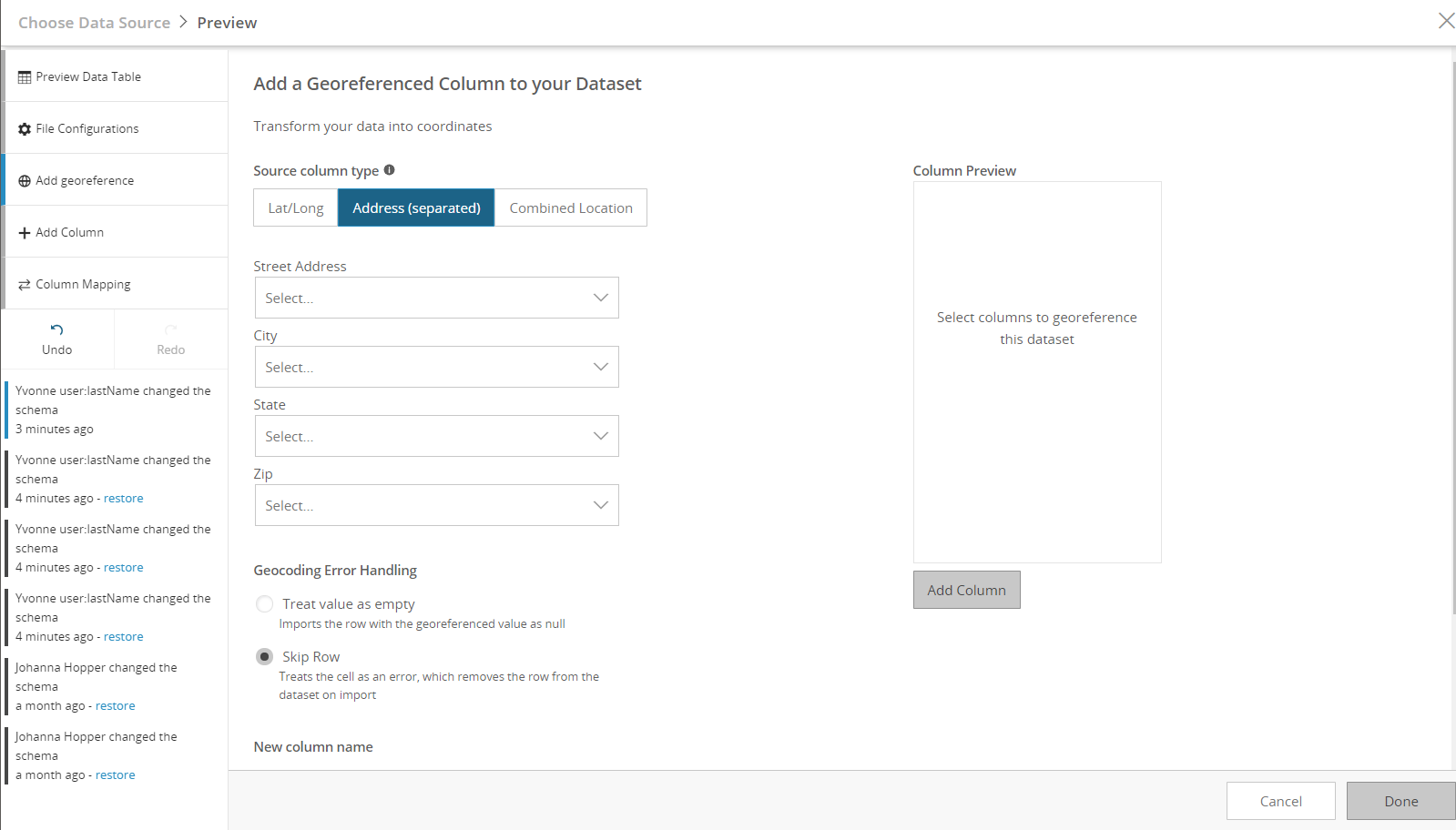
Adding a georeference column
From the data table preview, you can add a georeference column to your dataset using the component columns already in your dataset. There are three tabs that give options to create this column. Lat/Long can be used when you have both a column for latitude and longitude in your dataset. Address (separated) is used when fields such as street, city, state, and zip are separated out into different columns. And finally, Combined Address is used when there is a single column that contains the complete address.
There are a few other configuration options on this page as well. You can check Do not import original columns if you would like to remove the component columns from the dataset. There are also options to handle geocoding errors. Treat value as empty will still import the row and just treat the cell as blank in the dataset. Skip row will treat the row as an error and the entire row will not import to the dataset.
Finally, you can run the geocoder right from this window and preview how the column will display before deciding to publish your dataset.
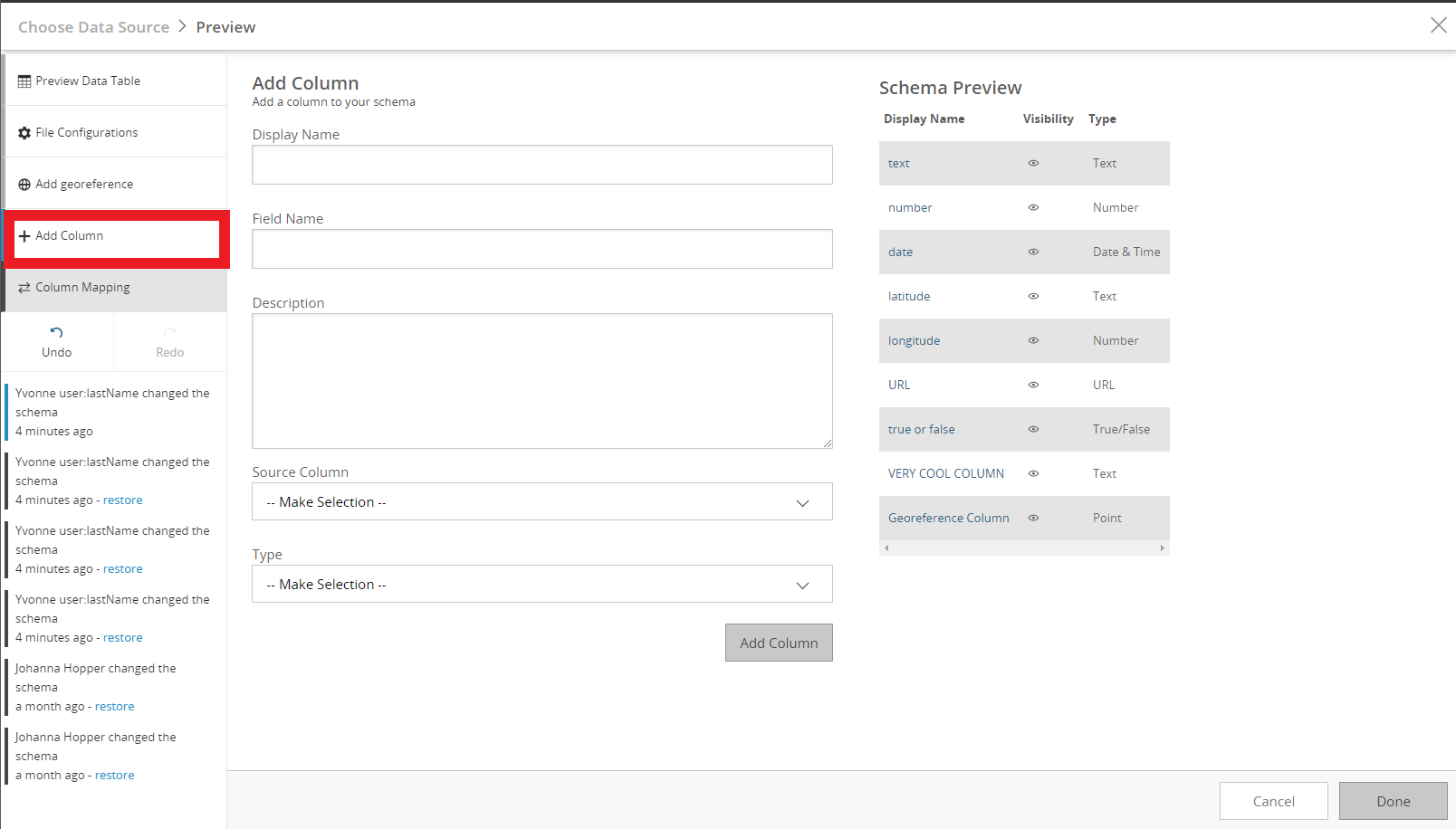
Adding a column
You can add new columns to your dataset by clicking on the Add Column button on the left-hand side of the data table preview. In this modal, you can add the display name, API field name, Description, source column, and data type of the new column.
Adding metadata
Before a dataset can be published, all required fields for the dataset metadata must be filled out. These fields can be accessed from the dataset draft page by clicking the Edit Metadata button.
Dataset metadata
Metadata is descriptive data about the dataset. Here are the different kinds of information you can provide about your platform dataset.
Dataset Title (required): The minimum amount of metadata required is a title for the platform dataset. This has to be unique from all other datasets and views on the site.
Brief Description: Any details you want to provide to elaborate on the title, even summarizing the different metadata information you are providing.
Category: You can select from a list of default categories which best encompasses the kind of data your dataset will hold. These defaults are "No category," "Business," "Education," "Fun," "Government," and "Personal." Administrators can configure more categories as options.
Tags and Keywords: You can add in words which will help make your dataset more searchable on the data portal. Multiple tags can be entered as comma-separated.
Licensing & Attribution: You can set the licensing terms for the data file, to appropriately reference your sources if people which to share it. To view the licensing options we support refer to the article Which licensing option should I use? You can name the Individual or Organization where you sourced the data from and provide a link if one is available.
Attachments: You will be able to attach files such as PDFs and images once the data file has already been imported by going to the About panel, then Edit Metadata once the data file has been fully imported. Attachments can be ordered in ascending or descending alphabetical value, or you can drag and drop attachments into a custom order.
Column metadata & ordering
Column metadata is descriptive information about the columns in the dataset. From this tab, you will also be able to edit the name and API field name of the dataset columns.
Note: Valid field name characters are all lower case, alphanumeric and underscore. It must start with a letter or underscore and cannot contain special characters or spaces.
Column names are limited to 255 characters (measured in code points). If your column name is longer than that an error will be shown.
In this tab, you can also set the visibility and set the order of columns in the dataset.
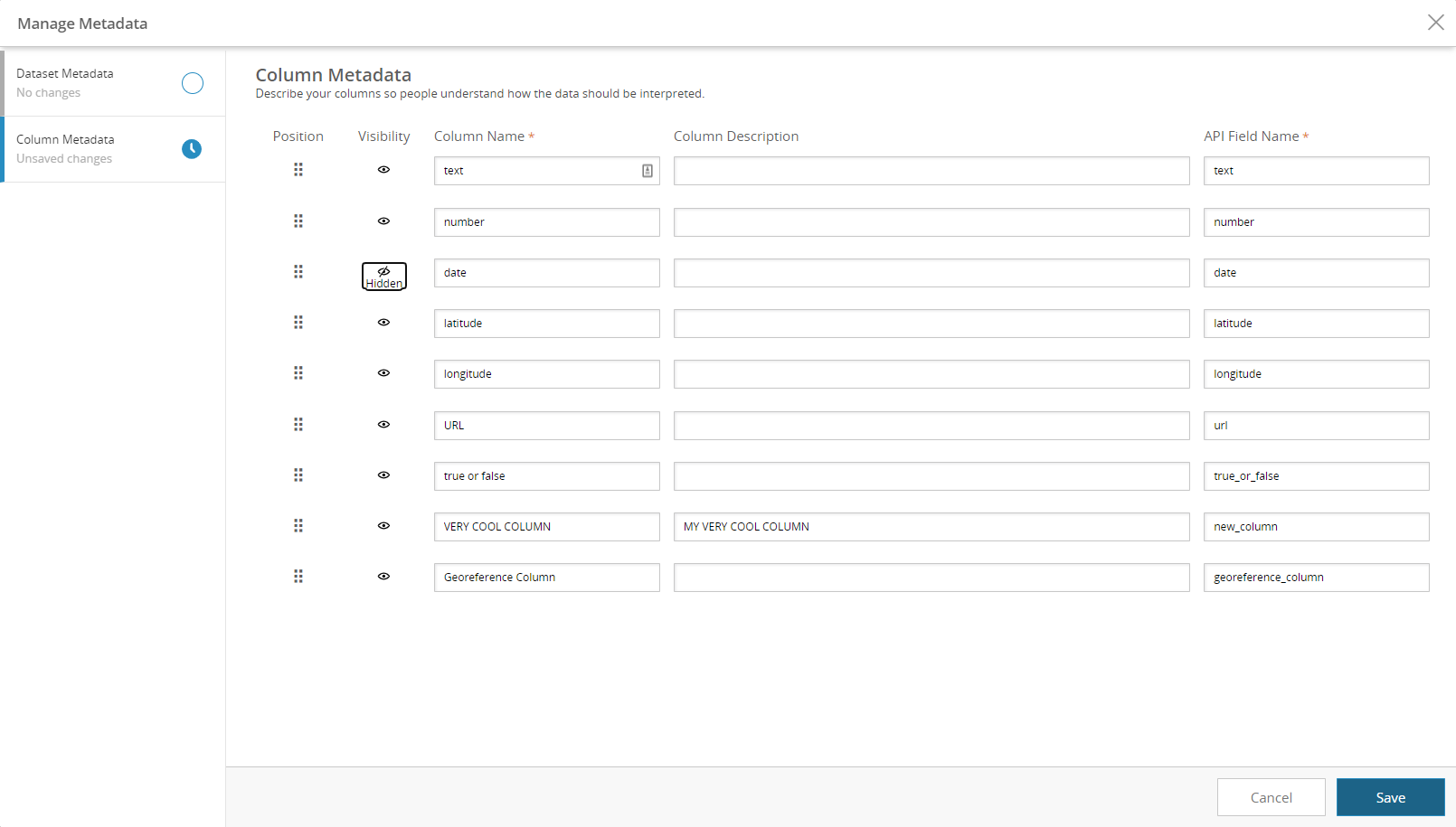
Column order is set by drag-and-drop, and visibility is set by toggling hidden and unhidden.
Collaboration and publishing
Prior to publishing the dataset, it will exist as a draft and can be accessed from the Asset Inventory. This allows you to complete different stages of the dataset at different times and can be completed by different contributors.
Review changes
When you click Update to submit changes to your draft, you will be prompted to review a summary of your changes. Any changes you've made to the dataset, such as adding new records, modifying the schema, changing the data source, etc., will be reflected in this Review Changes modal.
If any of the changes impact the dataset's schema, and the dataset has existing derived views dependent on it, you will see a mandatory confirmation message in this modal that asks you to acknowledge that your schema changes may impact those derived views.
Once you are finished creating the dataset and are ready to publish, click the Publish dataset... button on the action bar. Then, select the desired visibility permissions for the dataset and click Publish. Once you hit publish, you can move on from the page as the upload is now in progress. Once complete, you can select Go to Primer to view your brand new dataset.
You have now finished publishing a dataset using the Data & Insights Data Management Experience!
After a dataset is published, you can change the privacy of a dataset by navigating to the Manage panel > Permissions.
Comments
Article is closed for comments.